As AI tools get woven into more workflows, organizations have dramatically expanded both the volume of free-text data they process and the range of tasks they perform on it. This increased processing also expands the risk of leaking sensitive information contained in the text: a client's name, a phone number, payment details. To prevent this, it is good practice to remove sensitive information from text before using it. This involves two steps: finding the personal data in the text, then replacing and masking it in a way that preserves some of the meaning of the message. Both steps have their own specific challenges. In this article we will focus on detection.
While easy for a human, detecting sensitive information is a tough problem for a machine: Dates show up as "03/04/25", "March 4th", or "the fourth". Names get misspelled, shortened, or abbreviated. Account number formats are jurisdiction-specific. The detector needs to be flexible enough to cover all these cases while not being over-zealous and flag everything. On top of this, the detector also has to be quick: it usually sits in front of every LLM call, so any time it spends is time slowing down the user's response and experience.
In this article, we compare detection performances of three prominent open-source PII detectors: Microsoft Presidio, GLiNER, and OpenAI's Privacy Filter. All three are built on transformer models, the same family of neural networks behind modern LLMs. We measure their performances using two benchmark datasets in the English language and for a set of six PII categories which fall between the capabilities of all three detectors. Beside detection accuracy, we will also measure speed in terms of tokens/second.
The detectors
Presidio
Microsoft Presidio is an open-source framework for detecting and anonymizing personally identifiable information (PII) in unstructured text (recently also in images and structured data). First released in 2018, it is the more mature solution among the three considered here.
It combines several detection techniques rather than relying on a single model: regular expressions for pattern matching, Named Entity Recognition (NER) powered by NLP models like spaCy, checksum validation for entities like phone numbers and social security numbers, and a context-aware enhancer that boosts confidence based on surrounding words. It comes as a Python SDK with multi-language support and the possibility to expand and customize its recognizers.
GLiNER
GLiNER (Generalist and Lightweight model for Named Entity Recognition) takes a different approach. Instead of relying on a mix of pattern matching, rule-based components, and NER like Presidio, it uses a bidirectional transformer model in a zero-shot fashion: you provide the list of entity labels you want to extract at inference time (e.g. "passport number", "booking ID", "medical condition") and the model finds them without any retraining, which makes it much more flexible than traditional NER models that are locked to the categories they were trained on. This flexibility comes at a cost: finding the best configuration for a given use-case may require specific optimization.
It is distributed as a Python package with weights on Hugging Face and runs entirely locally. The models are small enough to run on modest hardware. Interestingly, it could be plugged into Presidio as an external recognizer to combine the strengths of both.
OpenAI Privacy Filter
OpenAI Privacy Filter (OPF) is the most recent of the three, released just a few months ago (April 2026) as an open-weight model. Like GLiNER it relies on a single bidirectional transformer. Unlike GLiNER however, OPF classifies each token into a fixed set of 8 privacy categories (private person, address, email, phone, URL, date, account number, and secret) and then combines the per-token labels back into coherent spans. The model supports a 128k-token context window and is derived from a small gpt-oss checkpoint with a total of 1.5B parameters using a sparse Mixture-of-Experts architecture with roughly 50M active parameters for efficiency.
Experimental Setup
Benchmark entities
When it comes to flexibility in the number and kind of entities they can detect, the three systems we are comparing vary greatly. GLiNER is by far the most flexible: to detect a new entity one just adds it to the list of labels at inference time. Presidio could also be configured by adding new recognizers, although with some engineering work. The OPF is the least configurable: the set of supported entities is fixed and can't be changed or expanded.
For this reason, when comparing the three systems we had to use the most restrictive set of entities derived from the entities supported by OPF. We have excluded "secret" as it could not be supported out-of-the-box by Presidio. The seven resulting entities and their description are presented in the table below. Several categories that Presidio (and GLiNER) handle natively such as credit card numbers or IBAN codes are combined into broader classes like ACCOUNT, or are not used by the detectors. While this allows for an apples-to-apples comparison, it also negates several advantages of the more flexible systems.
We will explore the limitations and implications of using broader PII categories in a separate post where we will investigate the effects of PII masking on AI systems.
Datasets
To provide ground truth labels for this benchmark, we use two publicly available PII-annotated
datasets: ai4privacy/pii-masking-400k and isotonic/pii-masking-200k. For each dataset, we
will use 10,000 samples in the English language. This will give us enough statistics to draw
firm conclusions, while keeping the experiments light.
ai4privacy/pii-masking-400k is an open synthetic dataset specifically designed to train and evaluate PII detection and masking models in LLM-oriented contexts. It covers a wide range of PII types such as names (split in given/surname), dates of birth, emails, phone numbers, credit card numbers, IDs, addresses, ZIP codes, passwords, IP addresses, social/tax numbers, and more. Notably, URLs in this dataset are not included among the PIIs.
isotonic/pii-masking-200k (train split) is another synthetic dataset, with a richer label set. It splits names into first / middle / last / prefix, adds more account subtypes (VINs, vehicle registration marks, BICs, masked numbers), and crucially includes URL, IP, IPV4, IPV6 and MAC labels. The distribution of entities in the samples of the two datasets is shown below. For each entity we have at least a few thousand examples combined, ensuring enough statistics to draw firm conclusions.
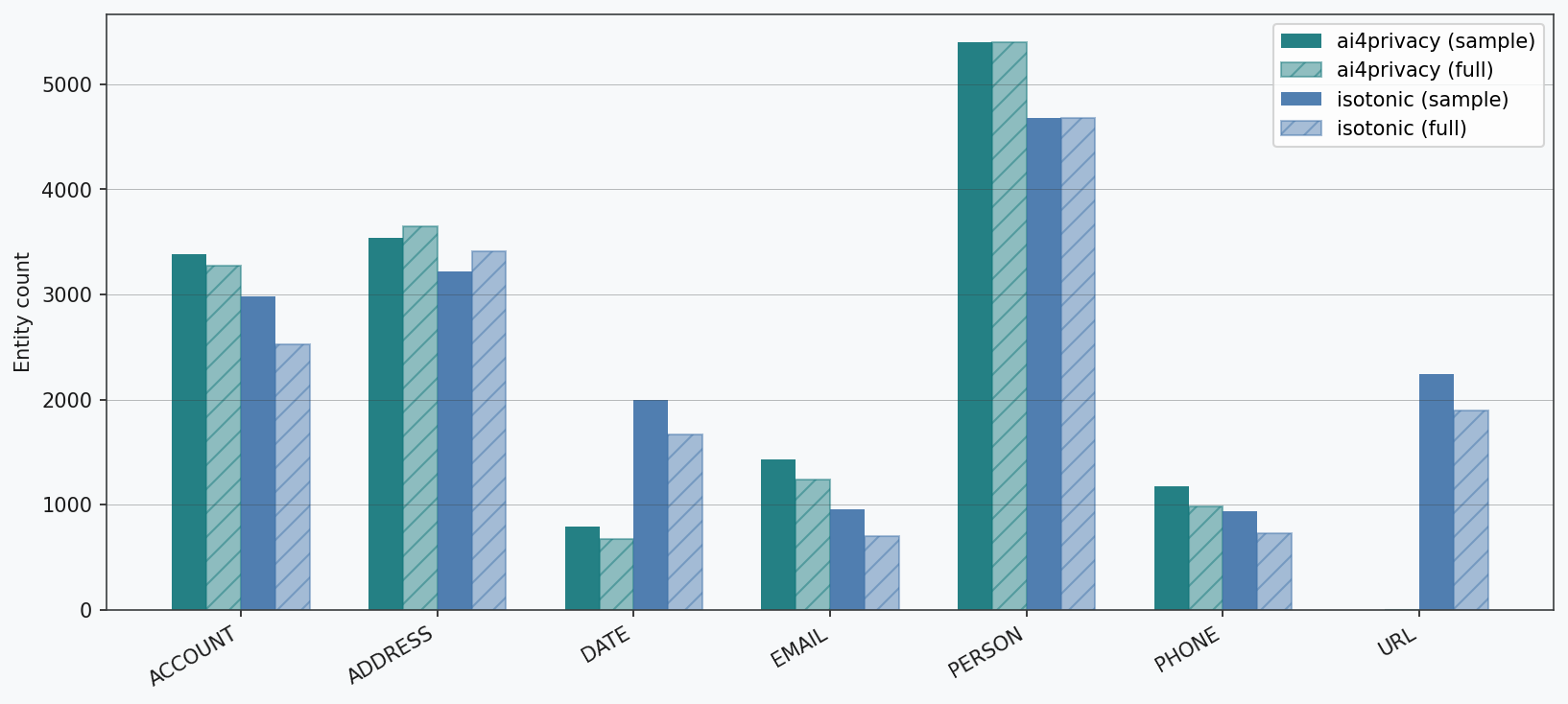
The figures below show how the rich taxonomy of each dataset gets mapped into our broader entity classes.
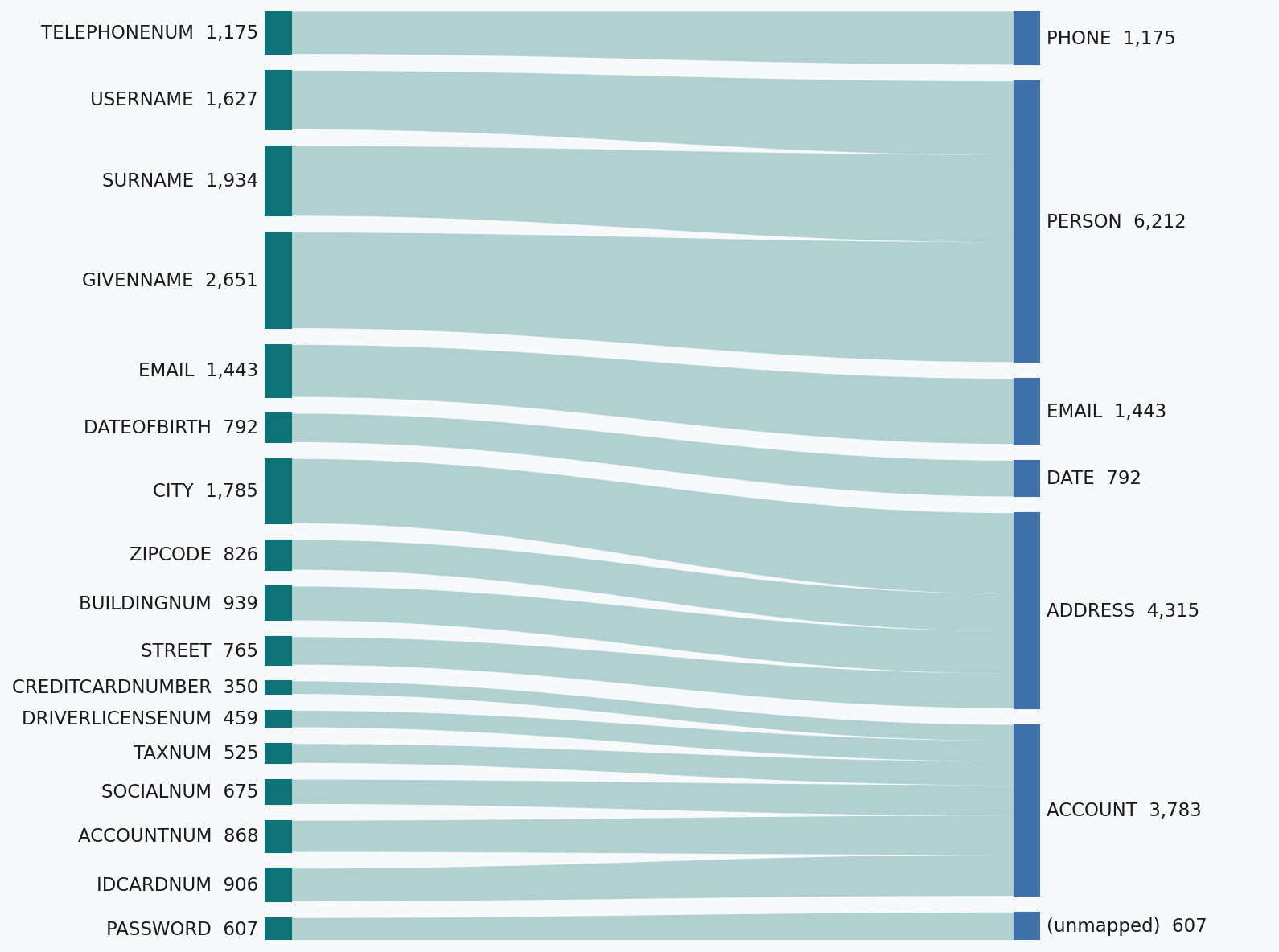
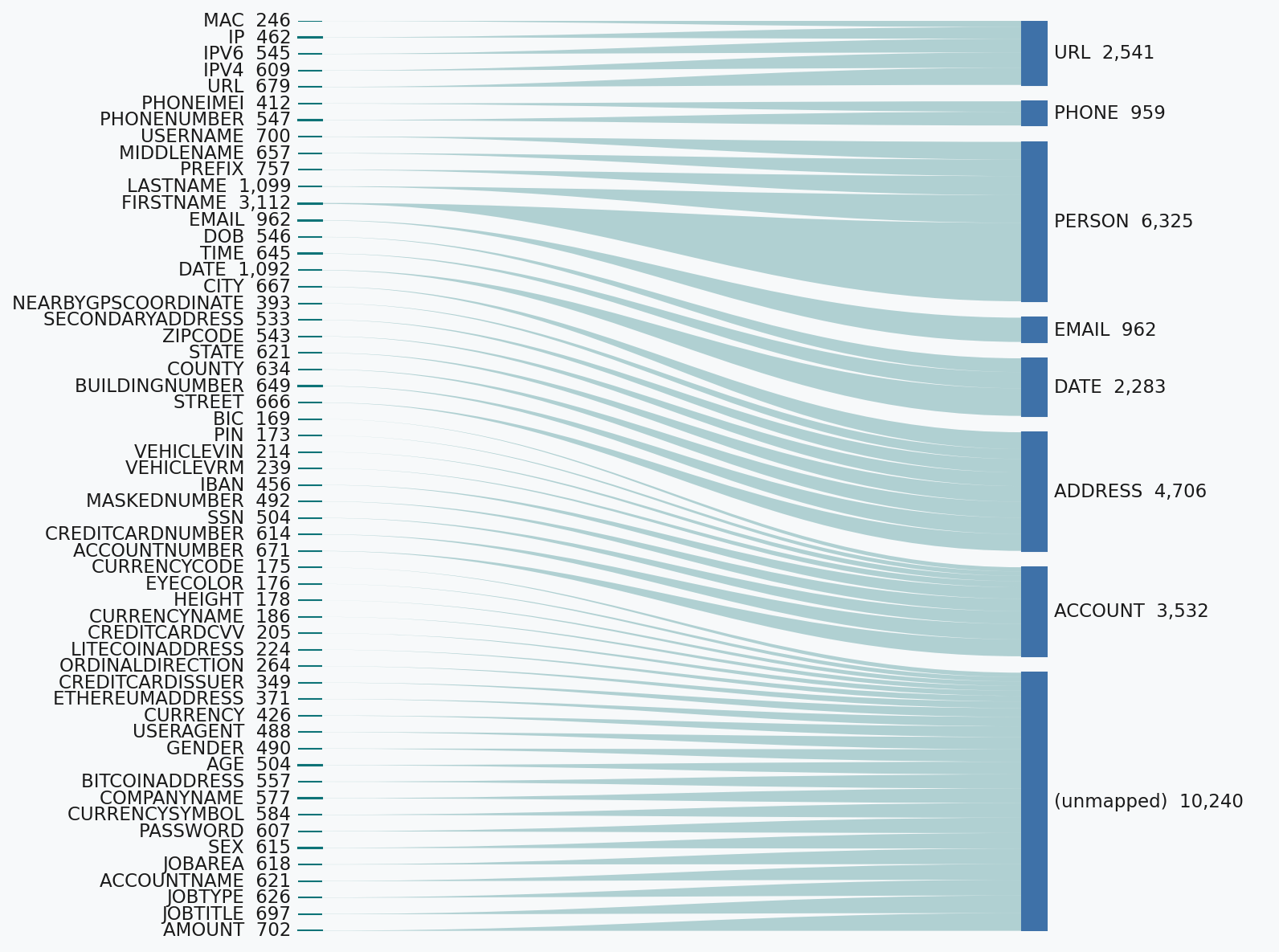
Detector configuration
The degree to which detection can be tuned varies among the three systems. For the sake of simplicity we chose to use them out of the box without any adjustment of thresholds or fine-tuning.
We run Presidio with spaCy's most capable NLP model (en_core_web_trf), a RoBERTa-based model
trained on English text. We use out-of-the-box Presidio recognizers to detect fine-grained
entities such as CREDIT_CARD, IBAN_CODE, US_SSN and collapse them into the seven
categories we use throughout this benchmark.
For GLiNER, we use the urchade/gliner_multi_pii-v1 model, which is explicitly tuned to detect
PIIs and natively covers 60+ sensitive entity types. Again, we define fine-grained labels and
map these back to the seven categories to compare with OPF. For consistency, we try to use the
same fine-grained labels as Presidio where possible.
For this benchmark we compare the three systems as "out of the box" as possible, without tuning any threshold or optimizing entity definitions and detectors. We leave exploring the optimization possibilities of each detector for future work.
Evaluation methodology
To compare detection performances with the ground truth we use the labeled mBERT (multilingual BERT) tokens provided by each dataset. Token-level comparison is more meaningful than checking for matches of entire spans because it is independent of the internal tokenization of the different detectors. For example, one model may flag "Dr. John Smith" as a PERSON while another would consider only "John Smith". If we were to compare spans, these very similar results would count as complete misses.
For each entity, detector, and dataset we compare precision and recall. Precision measures how many of the detected tokens are actually PII; Recall measures the fraction of PII tokens detected by the model over all tokens that truly were PII. A detector with low precision will lead to non-PII text being flagged as sensitive, destroying utility, while having low recall means leaking sensitive data. Precision and recall are combined together in the F1 score to provide a single number summarizing the performance of a detector.
Results
The results presented here are obtained running the benchmarks on a VM equipped with an A10 GPU.
Detection performances
The following figures present the performance of the three detectors on each dataset and entity type. Under "ALL" we report the micro-average of the metrics across all the entities.
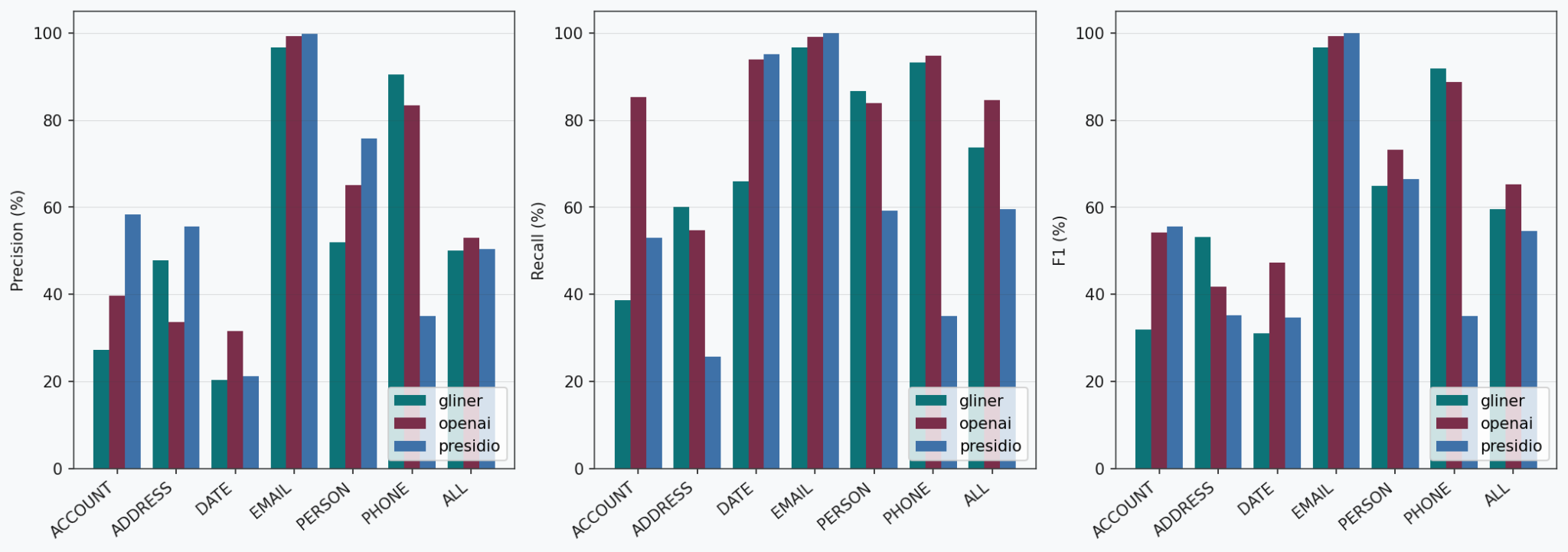
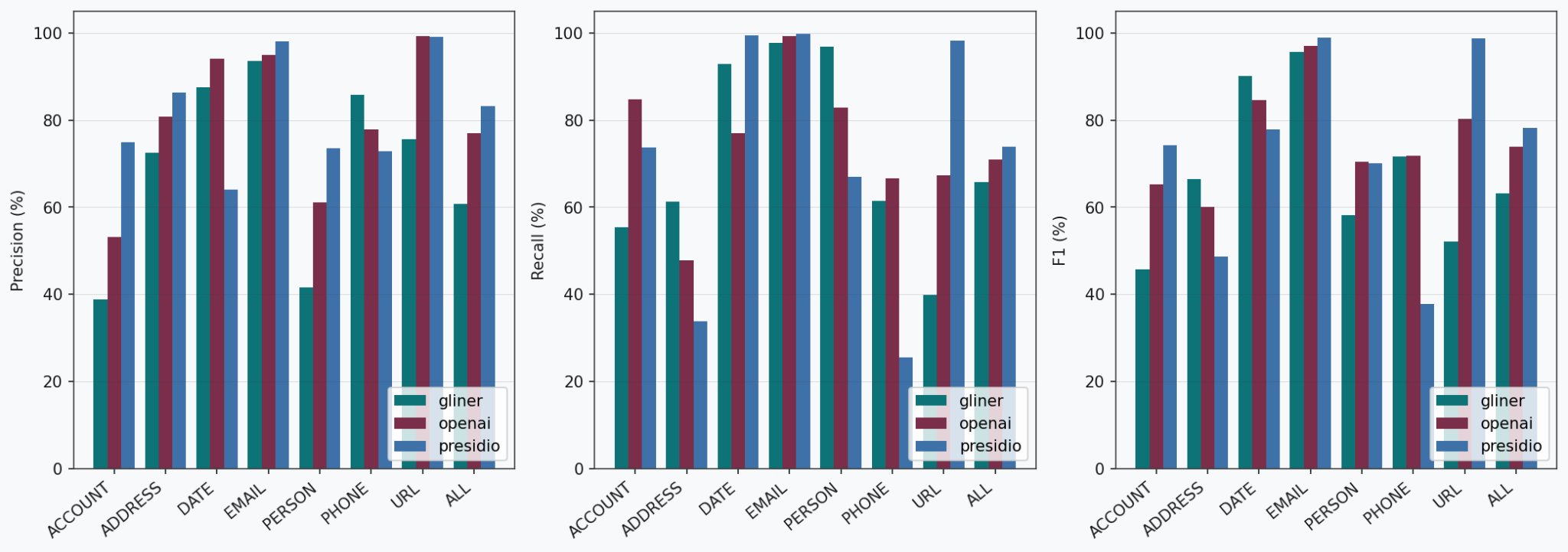
As visible, performances vary depending on entity type. Some entities such as email addresses are very easily recognized by all three systems, while others such as ADDRESS or ACCOUNT are more difficult to detect. Notably, the performance on DATE varies between datasets, with all three detectors performing more poorly on ai4privacy than on isotonic.
Looking at each detector: Presidio excels at detecting URLs thanks to its regex-based recognizers, while it struggles detecting phone numbers or addresses. GLiNER has consistently the best performance on ADDRESS while being the least effective for ACCOUNT, with both low precision and recall. OPF shows good overall performance across all datasets and entity types. Looking at the aggregated scores, Presidio is the strongest on isotonic while OPF leads on ai4privacy. For a deeper inspection of the results, confusion matrices are presented in the appendix.
Throughput
While running the benchmark we measured the time each detector took to process each text sample, and obtained a measure of throughput using the number of tokens of each text provided by the dataset.
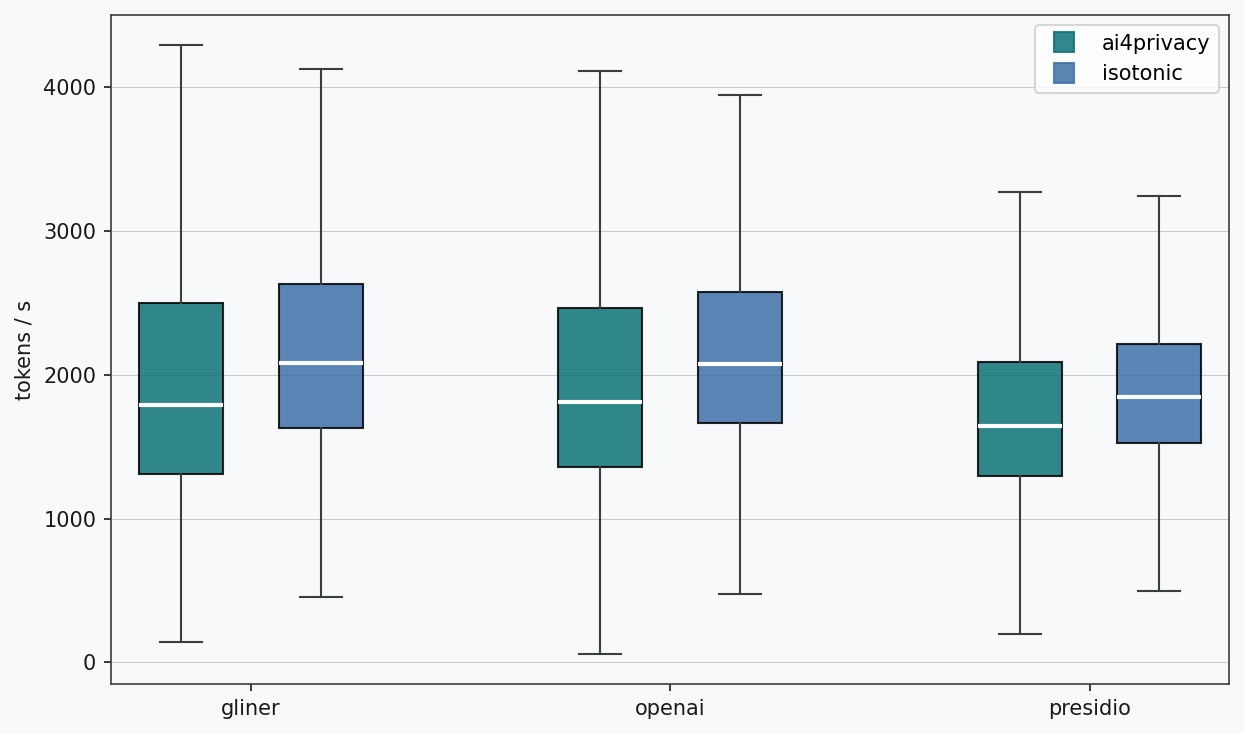
There is no significant difference in speed between the three detectors, with throughputs of roughly 2,000 tokens/sec. Presidio, with its mixture of NLP and pattern-based detectors, is slightly slower than GLiNER and OPF which run entirely on the GPU. Interestingly, detection seems slightly slower for the isotonic samples; this small difference could be due to the presence of the additional URL entity, absent in the ai4privacy benchmark.
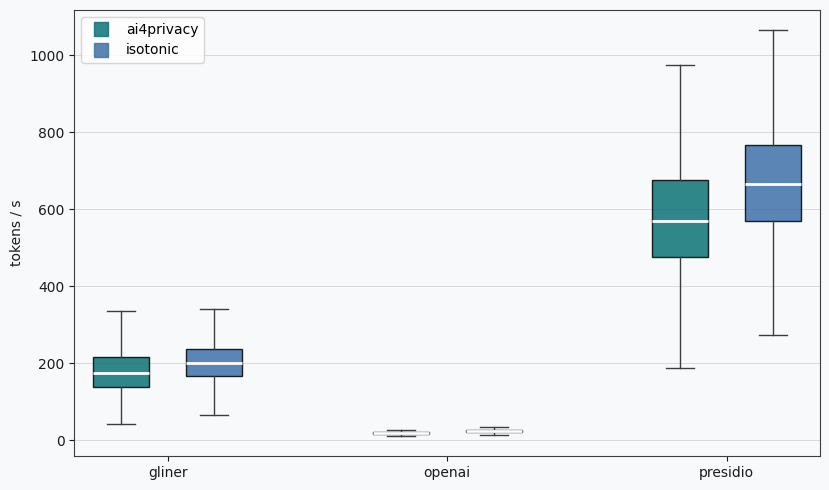
The A10 GPU is powerful enough to grant good throughput for all three detectors and make them well suited for online usage. The situation is very different when running on less powerful hardware or without a GPU. The figure below presents the throughput running the benchmark on a consumer-grade laptop without GPU and 16 GB of RAM. In this setup Presidio maintains a throughput of 500 tokens/s, while GLiNER manages roughly 200 tokens/s. OPF takes the biggest performance hit on CPU-only, managing only about 20 tokens per second.
Comparing detectors
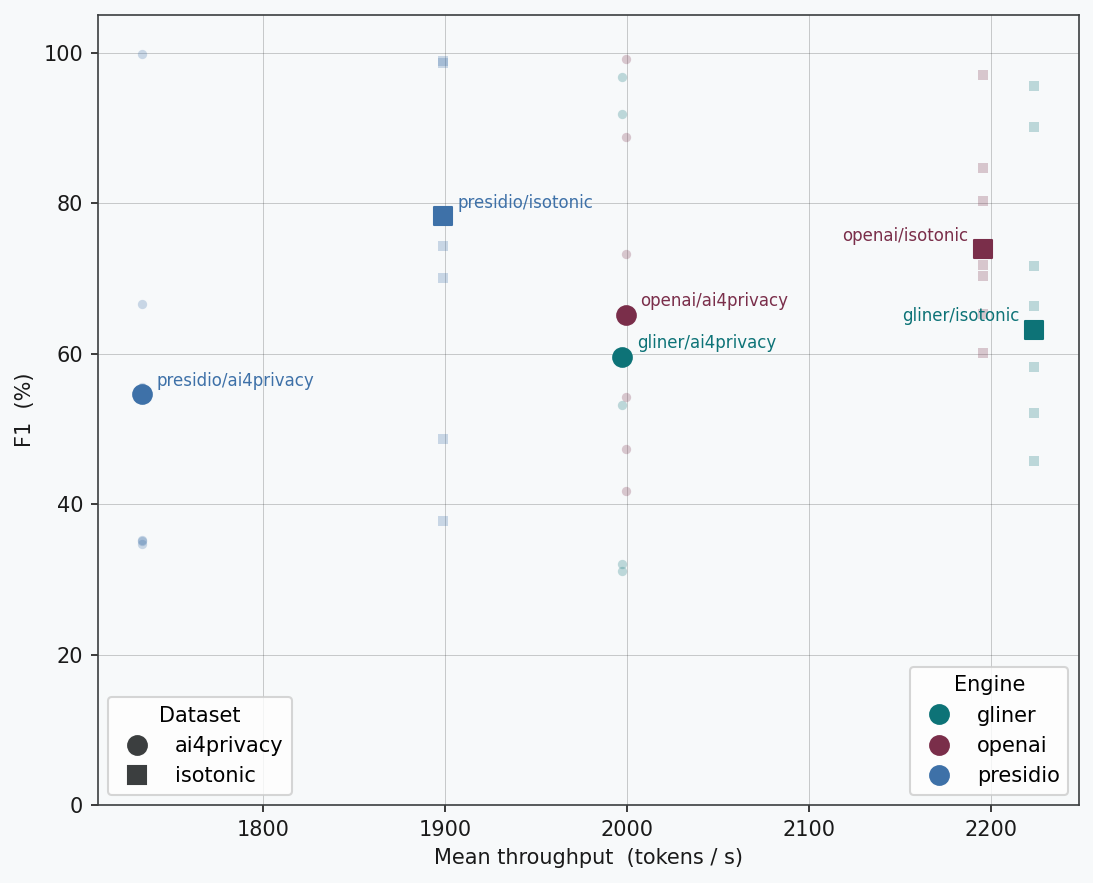
The following plot summarizes the main results of this benchmark, including detection performance (micro-averaged F1 score) and mean throughput. Presidio offers the widest range of variation, presenting both the best and the worst overall F1 score (for isotonic and ai4privacy, respectively). GLiNER and OPF are more consistent and similar in performance, with OPF providing better detection accuracy on both datasets while being only slightly slower than GLiNER.
Conclusions
The results discussed above show that detection performances depend greatly on entity type and even dataset, and that different detector engines perform better on different entities. Presidio shines on structured, pattern-rich entities like URLs and EMAIL thanks to its regex-based recognizers, GLiNER leads on ADDRESS detection, and OPF delivers the most balanced performance across entity types and datasets. On the A10 GPU, throughput differences are minor and all three detectors run at roughly 2,000 tokens/sec, making them all viable for online use in this setup.
Which detector to pick
The choice of the best detector depends on the deployment context and priorities. OPF is the strongest general-purpose pick, offering good detection performance and throughput right out of the box. However, if the workload involves a fixed, narrow set of well-structured entities (URLs, emails, credit cards, SSNs) or needs to run on CPU-only hardware, Presidio is to be preferred: it preserves a useful 500 tokens/sec on a laptop without GPU and outperforms the other detectors on entities that can be detected via pattern matching. Among the three detectors, GLiNER is the most flexible and easily configurable, supporting custom entity types and domain-specific labels out of the box without retraining.
Limitations and future directions
This benchmark was deliberately conservative: all three detectors were run out of the box, with no threshold tuning, fine-tuning, or entity-definition optimization, and we restricted ourselves to the lowest-common-denominator entity set imposed by OPF's fixed taxonomy. This negates much of the flexibility advantage of GLiNER and Presidio. The evaluation is also limited to the English language.
In a future piece, we will explore per-detector optimization (custom recognizers in Presidio, label engineering and threshold tuning in GLiNER) as well as the effects of using broad PII categories as OPF does (e.g. "account" instead of separate entities for IBAN codes, credit card numbers, etc.) on masking quality and LLM utility for downstream tasks.